LIFD Machine Learning For Earth Sciences








![]()
Leeds Institute for Fluid Dynamics (LIFD) has teamed up with the Centre for Environmental Modelling and Computation (CEMAC) team to create Jupyter notebook tutorials on the following topics.
- ConvolutionalNeuralNetworks
- Physics_Informed_Neural_Networks
- GaussianProcesses
- RandomForests
- GenerativeAdversarialNetworks
- AutoEncoders
- DimensionalityReduction
- XGBoost
These notebooks require very little previous knowledge on a topic and will include links to further reading where necessary. Each notebook will take about two hours to run through and should run out of the box on home installations of Jupyter notebooks.
How to Run
These notebooks can run with the resources provided and the Anaconda environment setup. If you are familiar with Anaconda, Jupyter notebooks and GitHub then simply clone this repository and run it within your Jupyter notebook setup. Otherwise, please read the how to run guide.
Convolutional Neural Networks
Classifying Volcanic Deformation
In this tutorial, we explore work done by Matthew Gaddes, creating a Convolutional Neural Network (CNN) that will detect and localise deformation in Sentinel-1 Interferograms. A database of labelled Sentinel-1 data hosted at VolcNet is used to train the CNN.

Physics-Informed Neural Networks
1D Heat Equation and Navier Stokes Equation
Recent developments in machine learning have gone hand in hand with a large growth in available data and computational resources. However, often when analysing complex physical systems, the cost of data acquisition can be prohibitively large. In this small data regime, the usual machine learning techniques lack robustness and do not guarantee convergence.
Fortunately, we do not need to rely exclusively on data when we have prior knowledge about the system at hand. For example, in a fluid flow system, we know that the observational measurements should obey the Navier-Stokes equations, and so we can use this knowledge to augment the limited data we have available. This is the principle behind physics-informed neural networks (PINNs).
These notebooks illustrate using PINNs to explore the 1D heat equation and Navier Stokes Equation.
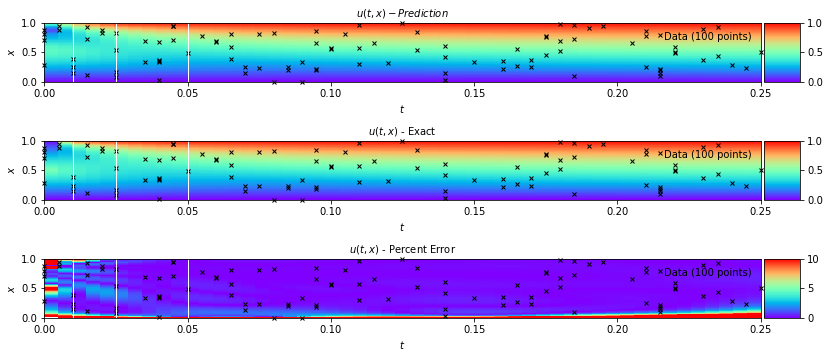
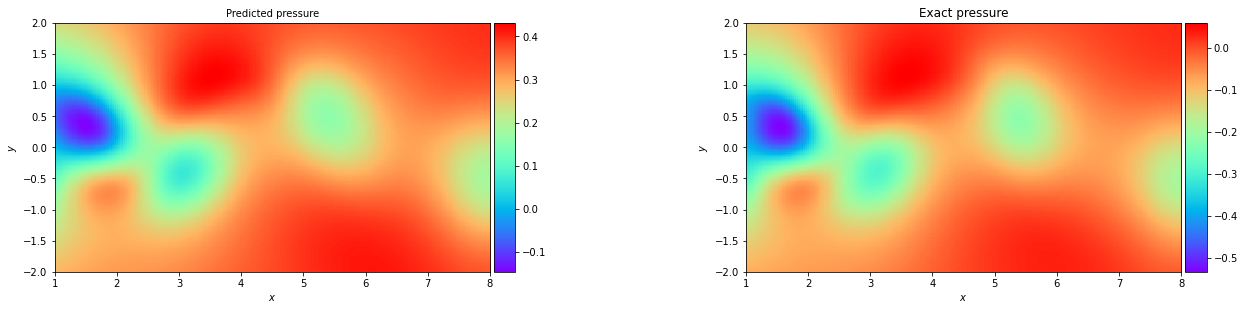
In the Navier Stokes example notebook, sparse velocity data points (blue dots) are used to infer fluid flow patterns in the wake of a cylinder and unknown velocity and pressure fields are predicted using only a discrete set of measurements of a concentration field c(t,x,y).
These examples are based on work from the following two papers:
- M. Raissi, P. Peridakis, G. Karniadakis, Physics Informed Deep Learning (Part II): Data-driven Discovery of Nonlinear Partial Differential Equations, 2017
- M. Raissi, A. Yazdani, G. Karniadakis, Hidden Fluid Mechanics: A Navier-Stokes Informed Deep Learning Framework for Assimilating Flow Visualization Data, 2018
Gaussian Processes
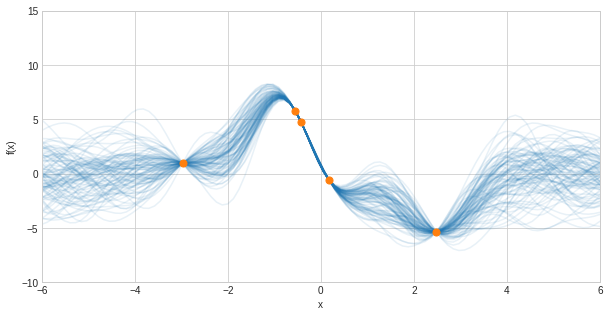
Exploring sea level change via Gaussian processes
Gaussian Processes are a powerful, flexible, and robust machine learning technique applied widely for prediction via regression with uncertainty. Implemented in packages for many common programming languages, Gaussian Processes are more accessible than ever for application to research within the Earth Sciences. In the notebook tutorial, we explore Oliver Pollard’s Sea level change work using Gaussian Processes.
Random Forests
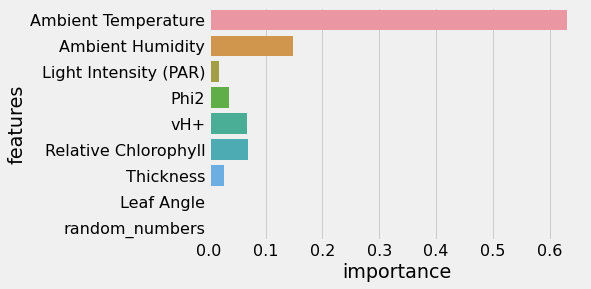
Identifying controls on leaf temperature via random forest feature importance
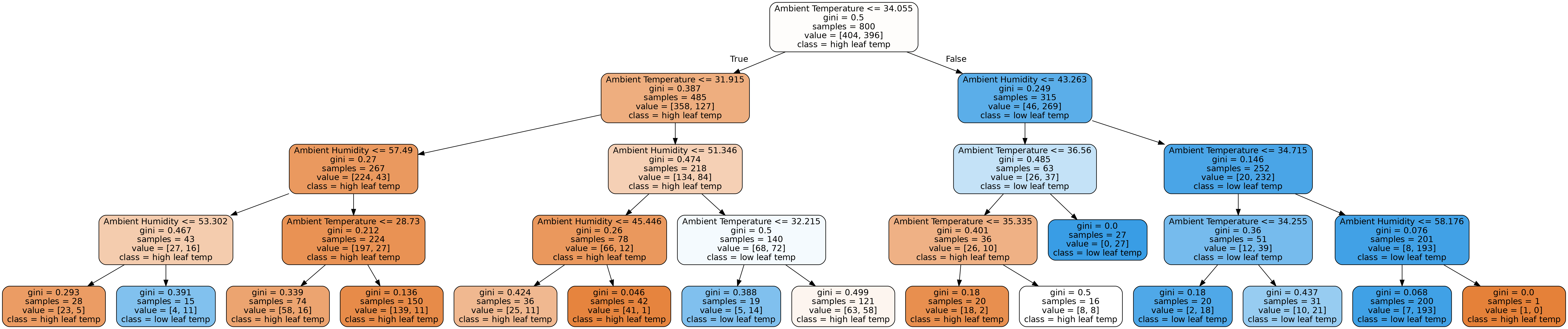
This tutorial is based on work done by Chetan Deva using Random Forests to predict leaf temperature from a number of measurable features.
Plants regulate their temperature in extreme environments. e.g. a plant in a desert can stay 18C cooler than the air temp or 22 C warmer than the air in the mountains. Leaf temperature differs from air temperature. Plant growth and development is strongly dependent on leaf temperature. Most Land Surface Models (LSMs) & Crop growth models (CGMs) use air temperature as an approximation of leaf temperature.
However, during time periods when large differences exist, this can be an important source of input data uncertainty.
In this tutorial leaf data containing a number of features is fed into a random forest regression model to evaluate which features are the most important to accurately predict the leaf temperature differential.
Generative Adversarial Networks
Generative Adversarial Networks
Generative Adversarial Networks are a pair of Neural Networks that work to generate rather than predict. The example you’ve probably see in mainstream media is deepfakes, where the network has been trained to produce images of humans that are so good even humans can’t tell the difference
Generative Adversarial Networks are made up of two Neural Networks: a generator and a discriminator. Both networks are equally bad at their respective tasks initially. As training continues, both networks compete with one another to get better at their respective tasks. Eventually, the generator becomes so good that humans can’t tell the difference (hopefully!)
Using PyTorch we can use the MNIST dataset to train a GAN to produce handwritten digits. Other applications of GANS are creating synthetic data such as generating synthetic tropical cyclone data (https://github.com/MetOffice/ML-TC), these can in turn be used to train other models.
AutoEncoders
AutoEncoders are unsupervised learning technique that performs data encoding and decoding using feed forward neural networks made of two components:
-
Encoder translates input data into lower dimensional space. (lower dimensional encoding is referred to as the latent space representation)
-
Decoder tries to reconstruct the original data from the lower dimensional data
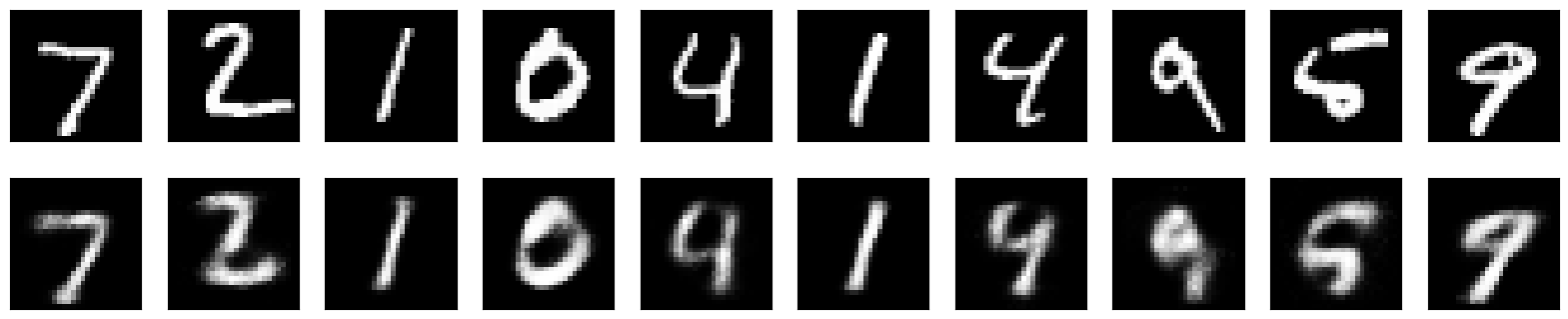
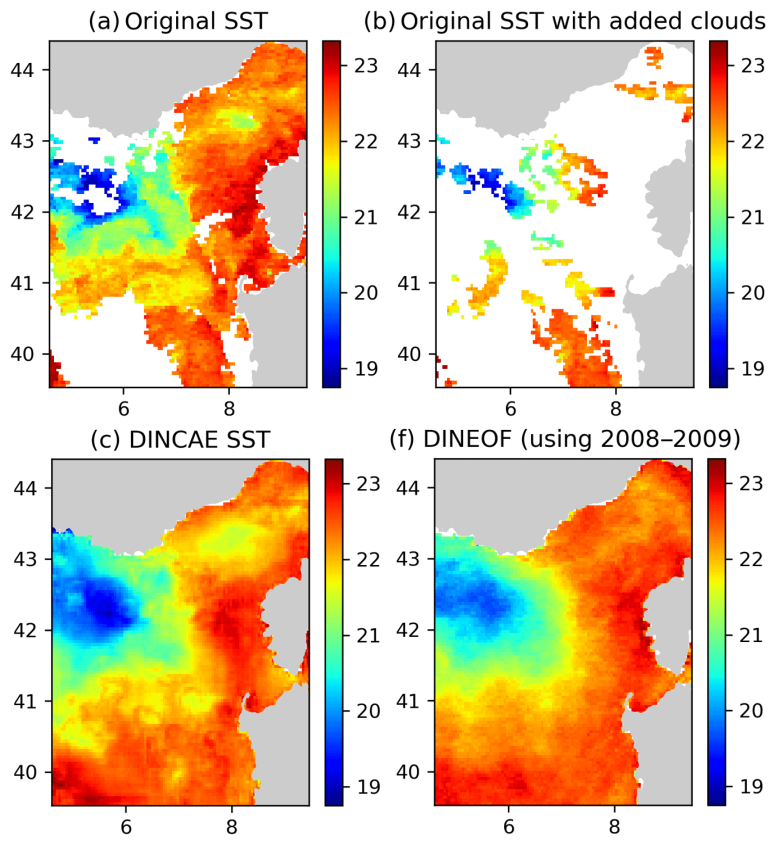
This can be used in simple examples such as encoding and decoding the MNSIT dataset or de-noising noisy digits. Which can then be applied for things such as using Auto Encoders to infill data for example in the case of Barth et al. 2020 they can earn non-linear, stochastic features measured at sea surface by satellite sensors so their use proves efficient in retaining small-scale structures that more traditional methods may remove / smooth out.
References:
- Barth et al 2020, Geoscientific Model Development: DINCAE 1.0: a convolutional neural network with error estimates to reconstruct sea surface temperature satellite observations.
eXtreme Gradient Boosting (XGBoost)
Predicting surface turbulent fluxes with gradient-boosted trees
XGBoost is a machine-learning library for training gradient-boosting models. Gradient boosting (or simply “boosting”) is a strategy for building ensemble estimators from decision trees. While similar to Random Forest in this regard, boosting methods are fundamentally different in the ways the trees are grown and their predictions combined.
In this tutorial notebook, we run through the process of fitting XGBoost models to tabular data, in order to predict surface turbulent fluxes over sea ice in the Arctic. This application to polar turbulent fluxes, inspired by the work of Cummins et al. (2023) and Cummins et al. (2024), is an example of a parametrization problem that is hard to solve with traditional physics, and illustrates how modern boosting methods allow us to easily obtain performant models.
References:
- Cummins, D. P., Guemas, V., Cox, C. J., Gallagher, M. R., & Shupe, M. D. (2023). Surface turbulent fluxes from the MOSAiC campaign predicted by machine learning. Geophysical Research Letters, 50(23), e2023GL105698.
- Cummins, D. P., Guemas, V., Blein, S., Brooks, I. M., Renfrew, I. A., Elvidge, A. D., & Prytherch, J. (2024). Reducing parametrization errors for polar surface turbulent fluxes using machine learning. Boundary-Layer Meteorology, 190(3), 13.
Contributions
We hope that this resource can be built upon to provide a wealth of training material for Earth-science machine-learning topics at Leeds.
Licence information

LIFD_ENV_ML_NOTEBOOKS by CEMAC is licensed under a Creative Commons Attribution 4.0 International License.
Acknowledgements
Leeds Institute of Fluid Dynamics, CEMAC, Helen Burns, Matthew Gaddes, Oliver Pollard, Chetan Deva, Fergus Shone, Michael MacRaild, Phil Livermore, Giulia Fedrizzi, Eszter Kovacs, Ana Reyna Flores, Francesca Morris, Emma Pearce, Maeve Murphy Quinlan, Sara Osman, Jonathan Coney, Eilish O’grady, Leif Denby, Sandra Piazolo, Caitlin Howarth, Claire Bartholomew, Anna Hogg, Ali Gooya, Tamora James and Donald Cummins.